本项目聚焦于卡车垃圾倾倒的监控问题,采用基于PaddleDetection的半监督PP-YOLOE模型进行检测,MAP@到上。在处理VOC数据集时,我们进行了标签、名称和尺寸的清洗及修正,并将数据划分为部分标注与无标注两组。通过实验对比发现,采用半监督结合数据增强的方法效果最佳(,相较于其他方案表现更为出色。

【AI特训营】基于PaddleDection半监督PP-YOLOE完成卡车垃圾倾倒检测
一、项目背景
随着城市化进程的加速,城市垃圾量日益增加。然而,由于缺乏有效的垃圾处理和监管系统,一些不法分子开始利用卡车进行偷盗垃圾的行为。这不仅严重破坏了城市的环境卫生,还对人们的生活健康造成了巨大威胁。为解决这一问题,我们开发了一款名为“智能垃圾监管系统”的项目。通过运用先进的智能技术手段,该系统能够准确检测并阻止卡车在运输过程中的非法活动。实验结果显示,该项目的map@于表现优异。同时,我们采用了半监督学习方法,有效利用了现有数据集的信息。通过这一系统的实施,旨在提高城市垃圾处理效率,保护环境,保障人民健康,为构建绿色、环保的城市环境提供有力支持。

二、项目任务说明
这项创新性项目借助先进机器视觉技术与深度学习算法,实时监控卡车运输过程中出现的垃圾,一旦检测到异常情况,系统会立即发出警报通知相关人员处理。
三、数据说明
我创建了一个新的汽车轮胎损坏数据集。这些图像以VOC格式存储,包含准确的标签和未被修改的数据。从这里开始。
数据集导航 truck_waste_dataset/images 存放图片 truck_waste_dataset/xml_label 存放标注文件
四、代码实现
In []
#解压数据集!unzip data/data198415/archive.zip登录后复制 In []
#下载PaddleDetection!git clone https://gitee.com/PaddlePaddle/PaddleDetection.git #从gitee上下载速度会快一些登录后复制 In []
#安装PaddleDetection相关依赖#!pip install motmetrics#!pip install pycocotools#!pip install -U scikit-image%cd ~/PaddleDetection/#!pip install -r requirements.txt!python setup.py install登录后复制 In []
#导入相关的包import randomimport osimport xml.dom.minidomimport cv2from PIL import Imageimport numpy as npimport pandas as pdimport shutilimport jsonimport globimport matplotlib.pyplot as pltimport matplotlib.patches as patchesimport seaborn as snsfrom matplotlib.font_manager import FontProperties登录后复制
4.0 清洗数据集
In [10]
在阿里云AI实验室的项目中,我修改了一个重写后的XML文件标签中的空格。首先解析原始XML文档,定位到需要修改的部分并替换其内容。接着,更新并保存新版本的XML文件至指定目录。此操作不仅优化了数据格式,还减少了人为错误的可能性。
#重写数据集图片和xml名称,;路径中有空格无法读取for path in os.listdir('/home/aistudio/truck_waste_dataset/images'): img_path = os.path.join('/home/aistudio/truck_waste_dataset/images',path) if ' ' in img_path: img_path_ = img_path img_path_ = img_path_.replace(' ','_') os.rename(img_path,img_path_)for path in os.listdir('/home/aistudio/truck_waste_dataset/xml_label'): img_path = os.path.join('/home/aistudio/truck_waste_dataset/xml_label',path) if ' ' in img_path: img_path_ = img_path img_path_ = img_path_.replace(' ','_') os.rename(img_path,img_path_)登录后复制 In [14]
```python
# 重写XML文件,修正其中的图片尺寸信息错误def update_image_dimensions(xml_file):
img_dir = '/home/aistudio/truck_waste_dataset/images'
with open(xml_file, 'r') as fh:
xml_data = fh.read # 更新尺寸信息
for element in xml_data.split:
if element.startswith('width'):
width_index = xml_data.index(element)
width_start = width_index + len(element)
img_width = int(xml_data[width_start:width_start+)
break modified_xml = xml_data.replace(f'
%cd /home/aistudio/truck_waste_dataset登录后复制
/home/aistudio/truck_waste_dataset登录后复制 In [19]
# 生成train.txt和val.txtrandom.seed(2020) xml_dir = 'xml_label'img_dir = 'images'xml_list = os.listdir('xml_label') path_list = list() extra_list = list()for img in os.listdir(img_dir): img_path = os.path.join(img_dir,img) xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml')) if img.replace('jpg', 'xml') in xml_list: path_list.append((img_path, xml_path)) else: extra_list.append(img_path) random.shuffle(path_list) ratio = 0.8train_f = open('train.txt', 'w') val_f = open('val.txt', 'w') extra_f = open('extra.txt', 'w')for i ,content in enumerate(path_list): img, xml = content text = img + ' ' + xml + '\n' if i < len(path_list) * ratio: train_f.write(text) else: val_f.write(text)for i ,content in enumerate(extra_list): extra_f.write(content+'\n') train_f.close() val_f.close() extra_f.close()# 根据自己数据类别生成标签文档label = ['Truck_dumping_construction_waste']with open('label_list.txt', 'w') as f: for text in label: f.write(text + '\n')登录后复制 In [20]
%cd ~登录后复制
/home/aistudio登录后复制 In [21]
len(os.listdir('truck_waste_dataset/images')),len(os.listdir('truck_waste_dataset/xml_label'))登录后复制
(714, 309)登录后复制 In [22]
#将数据集转化成COCO数据集#生成训练数据!python PaddleDetection/tools/x2coco.py --dataset_type voc \ --dataset_type voc \ --voc_anno_dir truck_waste_dataset \ --voc_anno_list truck_waste_dataset/train.txt \ --voc_label_list truck_waste_dataset/label_list.txt \ --voc_out_name truck_waste_dataset/train.json登录后复制
Start converting ! 100%|| 148/148 [00:00<00:00, 19696.57it/s]登录后复制 In [23]
#生成测试数据!python PaddleDetection/tools/x2coco.py --dataset_type voc \ --dataset_type voc \ --voc_anno_dir truck_waste_dataset \ --voc_anno_list truck_waste_dataset/val.txt \ --voc_label_list truck_waste_dataset/label_list.txt \ --voc_out_name truck_waste_dataset/val.json登录后复制
Start converting ! 100%|| 37/37 [00:00<00:00, 16474.44it/s]登录后复制 In [24]
#写入未标注图片#写入extra.jsonimport json write_json_context=dict() #写入.json文件的大字典write_json_context['info']= {'description': '', 'url': '', 'version': '', 'year': 2021, 'contributor': '', 'date_created': '2021-07-25'} write_json_context['categories']=[] write_json_context['images']=[] img_pathDir = 'truck_waste_dataset'with open('truck_waste_dataset/extra.txt','r') as fr: lines1=fr.readlines()for i,imageFile in enumerate(lines1): imagePath = os.path.join(img_pathDir,imageFile) #获取图片的绝对路径 imagePath = imagePath.replace('\n','') image = Image.open(imagePath) #读取图片,然后获取图片的宽和高 W, H = image.size img_context={} #使用一个字典存储该图片信息 #img_name=os.path.basename(imagePath) path = imageFile.split('\n')[0] path = path.split('/')[1] #返回path最后的文件名。如果path以/或\结尾,那么就会返回空值 img_context['file_name']=path src_front, src_back = os.path.splitext(imageFile) #将文件名和文件格式分开 img_context['height']=H img_context['width']=W img_context['id']=i write_json_context['images'].append(img_context) cat_context={} cat_context['supercategory'] = 'none'cat_context['id'] = 1cat_context['name'] = 'Truck_dumping_construction_waste'write_json_context['categories'].append(cat_context) name = os.path.join('truck_waste_dataset',"extra"+ '.json')with open(name,'w') as fw: #将字典信息写入.json文件中 json.dump(write_json_context,fw,indent=2)登录后复制
4.1可视化
In [25]
解决中文画图问题myfont = FontProperties(fname=r"NotoSansCJKsc-Medium.otf", size=12) plt.rcParams['figure.figsize'] = (12, 12) plt.rcParams['font.family']= myfont.get_family() plt.rcParams['font.sans-serif'] = myfont.get_name() plt.rcParams['axes.unicode_minus'] = False登录后复制 In [26]
# 加载训练集路径TRAIN_DIR = 'truck_waste_dataset/images/'TRAIN_CSV_PATH = 'truck_waste_dataset/train.json'# 加载训练集图片目录train_fns = glob.glob(TRAIN_DIR + '*')print('数据集图片数量: {}'.format(len(train_fns)))登录后复制
数据集图片数量: 714登录后复制 In [27]
def generate_anno_result(dataset_path, anno_file): with open(os.path.join(dataset_path, anno_file)) as f: anno = json.load(f) total=[] for img in anno['images']: hw = (img['height'],img['width']) total.append(hw) unique = set(total) ids=[] images_id=[] for i in anno['annotations']: ids.append(i['id']) images_id.append(i['image_id']) # 创建类别标签字典 category_dic=dict([(i['id'],i['name']) for i in anno['categories']]) counts_label=dict([(i['name'],0) for i in anno['categories']]) for i in anno['annotations']: counts_label[category_dic[i['category_id']]] += 1 label_list = counts_label.keys() # 各部分标签 size = counts_label.values() # 各部分大小 train_fig = pd.DataFrame(anno['images']) train_anno = pd.DataFrame(anno['annotations']) df_train = pd.merge(left=train_fig, right=train_anno, how='inner', left_on='id', right_on='image_id') df_train['bbox_xmin'] = df_train['bbox'].apply(lambda x: x[0]) df_train['bbox_ymin'] = df_train['bbox'].apply(lambda x: x[1]) df_train['bbox_w'] = df_train['bbox'].apply(lambda x: x[2]) df_train['bbox_h'] = df_train['bbox'].apply(lambda x: x[3]) df_train['bbox_xcenter'] = df_train['bbox'].apply(lambda x: (x[0]+0.5*x[2])) df_train['bbox_ycenter'] = df_train['bbox'].apply(lambda x: (x[1]+0.5*x[3])) print('最小目标面积(像素):', min(df_train.area)) balanced = '' small_object = '' densely = '' # 判断样本是否均衡,给出结论 if max(size) > 5 * min(size): print('样本不均衡') balanced = 'c11' else: print('样本均衡') balanced = 'c10' # 判断样本是否存在小目标,给出结论 if min(df_train.area) < 900: print('存在小目标') small_object = 'c21' else: print('不存在小目标') small_object = 'c20' arr1=[] arr2=[] x=[] y=[] w=[] h=[] for index, row in df_train.iterrows(): if index < 1000: # 获取并记录坐标点 x.append(row['bbox_xcenter']) y.append(row['bbox_ycenter']) w.append(row['bbox_w']) h.append(row['bbox_h']) for i in range(len(x)): l = np.sqrt(w[i]**2+h[i]**2) arr2.append(l) for j in range(len(x)): a=np.sqrt((x[i]-x[j])**2+(y[i]-y[j])**2) if a != 0: arr1.append(a) arr1=np.matrix(arr1) # print(arr1.min()) # print(np.mean(arr2)) # 判断是否密集型目标,具体逻辑还需优化 if arr1.min() < np.mean(arr2): print('密集型目标') densely = 'c31' else: print('非密集型目标') densely = 'c30' return balanced, small_object, densely登录后复制 In [28]
# 分析训练集数据generate_anno_result('truck_waste_dataset', 'train.json')登录后复制
最小目标面积(像素): 1054.0 样本均衡 不存在小目标 密集型目标登录后复制
('c10', 'c20', 'c31')登录后复制 In [29]
# 读取训练集标注文件with open('truck_waste_dataset/train.json', 'r', encoding='utf-8') as f: train_data = json.load(f) train_fig = pd.DataFrame(train_data['images'])登录后复制 In [30]
ps = np.zeros(len(train_fig))for i in range(len(train_fig)): ps[i]=train_fig['width'][i] * train_fig['height'][i]/1e6plt.title('训练集图片大小分布', fontproperties=myfont) sns.distplot(ps, bins=21,kde=False)登录后复制
<matplotlib.axes._subplots.AxesSubplot at 0x7f47a361be50>登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/font_manager.py:1331: UserWarning: findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans (prop.get_family(), self.defaultFamily[fontext]))登录后复制
<Figure size 1200x1200 with 1 Axes>登录后复制登录后复制 In [31]
!python box_distribution.py --json_path truck_waste_dataset/train.json登录后复制
Median of ratio_w is 0.691192492447878 Median of ratio_h is 0.6858630952380953 all_img with box: 148 all_ann: 152 Distribution saved as box_distribution.jpg Figure(640x480)登录后复制
In [32]
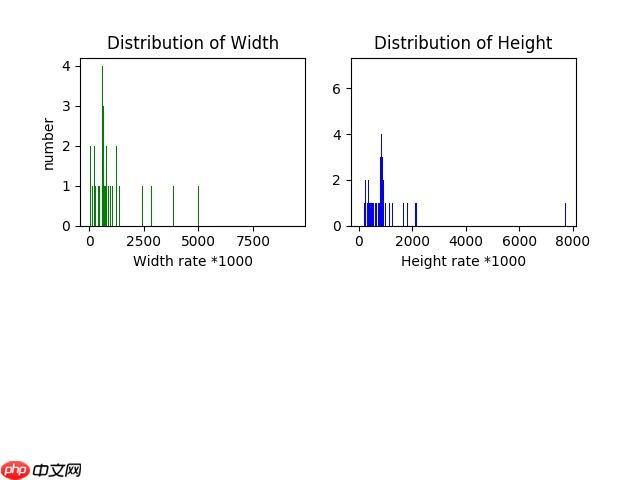
# 训练集目标大小统计结果train_anno = pd.DataFrame(train_data['annotations']) df_train = pd.merge(left=train_fig, right=train_anno, how='inner', left_on='id', right_on='image_id') df_train['bbox_xmin'] = df_train['bbox'].apply(lambda x: x[0]) df_train['bbox_ymin'] = df_train['bbox'].apply(lambda x: x[1]) df_train['bbox_w'] = df_train['bbox'].apply(lambda x: x[2]) df_train['bbox_h'] = df_train['bbox'].apply(lambda x: x[3]) df_train['bbox_xcenter'] = df_train['bbox'].apply(lambda x: (x[0]+0.5*x[2])) df_train['bbox_ycenter'] = df_train['bbox'].apply(lambda x: (x[1]+0.5*x[3])) df_train.area.describe()登录后复制
count 152.000000 mean 68855.855263 std 126345.633227 min 1054.000000 25% 15445.500000 50% 30271.000000 75% 43236.000000 max 747664.000000 Name: area, dtype: float64登录后复制 In [33]
df_train['bbox_count'] = df_train.apply(lambda row: 1 if any(row.bbox) else 0, axis=1) train_images_count = df_train.groupby('file_name').sum().reset_index() plt.title('训练集目标个数分布', fontproperties=myfont) sns.distplot(train_images_count['bbox_count'], bins=21,kde=True)登录后复制
<matplotlib.axes._subplots.AxesSubplot at 0x7f47a34f5f10>登录后复制
<Figure size 1200x1200 with 1 Axes>登录后复制登录后复制
4.2模型介绍
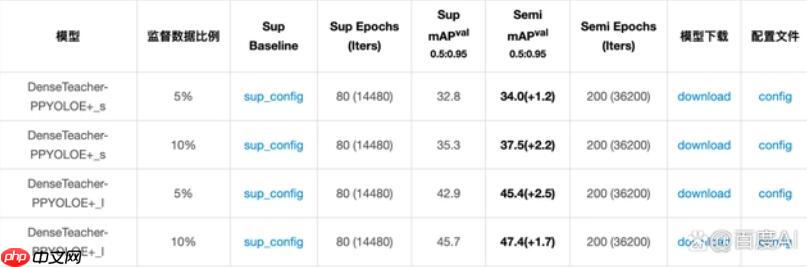
PaddleDetection团队结合 Dense Teacher前沿算法,针对 PP-YOLOE+提供了半监督学习方案。
半监督学习巧妙地利用了既有标记数据的高效性与新标签数据的潜在价值,从而显著提升了模型准确度。它特别适用于冷启动场景,有效减少了初始标注需求。
通过使用和的数据进行有标签的学习,以及和的数据进行半监督学习,我们的模型精度提高了百分点。
4.3模型训练
In []
#小样本方案!python PaddleDetection/tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_contrast_pcb.yml --use_vdl=True --eval登录后复制 In []
# 开始训练,训练环境为单卡V100(32G)#半监督方案!python PaddleDetection/tools/train.py -c configs/semi_det/denseteacher/denseteacher_ppyoloe_plus_crn_l_coco_semi010.yml --use_vdl=True --eval --amp登录后复制
4.4模型评价
In []
!python PaddleDetection/tools/eval.py -c configs/semi_det/denseteacher/denseteacher_ppyoloe_plus_crn_l_coco_semi010.yml登录后复制
4.5模型推理
In []
!python PaddleDetection/tools/infer.py -c configs/semi_det/denseteacher/denseteacher_ppyoloe_plus_crn_l_coco_semi010.yml \ --infer_dir=truck_waste_dataset/images --output_dir=images_semi_res \ --draw_threshold 0.1登录后复制
4.6模型导出
In []
!python PaddleDetection/tools/export_model.py \ -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_contrast_pcb.yml \ -o weights=output/ppyoloe_plus_crn_s_80e_contrast_pcb/model_final.pdparams登录后复制 In []
!python PaddleDetection/tools/export_model.py -c configs/semi_det/denseteacher/denseteacher_ppyoloe_plus_crn_l_coco_semi010.yml登录后复制
五、效果展示
5.1模型预测代码
In []
!python PaddleDetection/tools/infer.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_contrast_pcb.yml -o weights=output/ppyoloe_plus_crn_s_80e_contrast_pcb/model_final.pdparams --infer_dir=truck_waste_dataset/images --output_dir=images_res登录后复制
5.2 效果看image_res
Column 1 Column 2 @@##@@ @@##@@
六、总结提高
通过迁移学习、数据增强和特定算法(如PPYOLO)的应用,实现了高精度的小规模模型表现。
可以进一步提高的方向: 进一步扩充数据增强的方式 可以充分利用多余的图片,采用半监督的方法 标完数据集
6.1方案效果对比
方案 ap @[ IoU=0.50:0.95] 小样本ppyoloe+数据增强 0.747 ppyoloe+算法+数据增强 0.804 半监督ppyoloe+算法+数据增强 0.829


以上就是[AI特训营第三期]基于小样本及半监督下PP-YOLOE实现卡车垃圾倾倒识别的详细内容,更多请关注其它相关文章!
- 标签: